
There are a plethora of articles on Deep Learning (DL) or Machine Learning (ML) that cover topics like data gathering, data munging, network/algorithm selection, training, validation, and evaluation. But, one of the challenging problems in today’s data science is the deployment of the trained model in production for any consumer-centric organizations or individuals who want to make their solutions reach a wider audience.
Most of the time, energy and resources are spent on training the model to achieve the desired results, so allocating additional time and energy to decide on the computational resources to set up the appropriate infrastructure to replicate the model for achieving similar results in a different environment (production) at scale will be a difficult task. Overall, it’s a lengthy process that can easily take up months right from the decision to use DL to deploying the model.
This article tries to give a comprehensive overview of the entire process of deployment from scratch. Also, please feel free to comment below in case I miss something.

Illustration of the workflow (from client API requests to server prediction responses). You are free to use the image.
Note: The above image is just an illustration of a probable architecture and used primarily for learning purpose.
Components
Let’s break down the above image that depicts the entire API workflow and understand every component.
- Client: The client in the architecture can be any device or a third party application that tries to request the server hosting the architecture for model predictions. Example: Facebook trying to tag your face on a newly uploaded image.
- Load Balancer: A load balancer tries to distribute the workload (requests) across multiple servers or instances in a cluster. The aim of the load balancer is to minimize the response time and maximize the throughput by avoiding the overload on any single resource. In the above image, the load balancer is public facing entity and distributes all the requests from the clients to multiple Ubuntu servers in the cluster.
- Nginx: Nginx is an open-source web server but can also be used as a load balancer. Nginx has a reputation for its high performance and small memory footprint. It can thrive under heavy load by spawning worker processes, each of which can handle thousands of connections. In the image, nginx is local to one server or instance to handle all the requests from the public facing load balancer. An alternative to nginx is Apache HTTP Server.
- Gunicorn: It is a Python Web Server Gateway Interface (WSGI) HTTP server. It is ported from Ruby’s Unicorn project. It is a pre-fork worker model, which means a master creates multiple forks which are called workers to handle the requests. Since Python is not multithreaded, we try to create multiple gunicorn workers which are individual processes that have their own memory allocations to compensate the parallelism for handling requests. Gunicorn works for various Python web frameworks and a well-known alternative is uWSGI.
- Flask: It is a micro web framework written in Python. It helps us to develop application programming interface (API) or a web application that responds to the request. Other alternatives to Flask are Django, Pyramid, and web2py. An extension of Flask to add support for quickly building REST APIs is provided by Flask-RESTful.
- Keras: It is an open-source neural network library written in Python. It has the capability to run on top of TensorFlow, CNTK, Theano or MXNet. There are plenty of alternatives to Keras: TensorFlow, Caffe2 (Caffe), CNTK, PyTorch, MXNet, Chainer, and Theano (discontinued).
- Cloud Platform: If there is one platform that intertwines all the above-mentioned components, then it is the cloud. It is one of the primary catalysts for the proliferation in the research of Artificial Intelligence, be it Computer Vision, Natural Language Processing, Machine Learning, Machine Translation, Robotics or Medical Imaging. Cloud has made computational resources accessible to a wider audience at a reasonable cost. Few of the well-known cloud web services are Amazon Web Services (AWS), Google Cloud and Microsoft Azure.
Architecture Setup
By now you should be familiar with the components mentioned in the previous section. In the following section, Let’s understand the setup from an API perspective since this forms the base for a web application as well.
Note: This architecture setup will be based on Python.
Development Setup
- Train the model: The first step is to train the model based on the use case using Keras or TensorFlow or PyTorch. Make sure you do this in a virtual environment, as it helps in isolating multiple Python environments and also it packs all the necessary dependencies into a separate folder.
- Build the API: Once the model is good to go into an API, you can use Flask or Django to build them based on the requirement. Ideally, you have to build Restful APIs, since it helps in separating between the client and the server; improves visibility, reliability, and scalability; it is platform agnostic. Perform a thorough test to ensure the model responds with the correct predictions from the API.
- Web Server: Now is the time to test the web server for the API that you have built. Gunicorn is a good choice if you have built the APIs using Flask. An example command to run the gunicorn web server.
gunicorn --workers 1 --timeout 300 --bind 0.0.0.0:8000 api:app- workers (INT): The number of worker processes for handling requests.
- timeout (INT): Workers silent for more than this many seconds are killed and restarted.
- bind (ADDRESS): The socket to bind. [['127.0.0.1:8000']]
- api: The main Python file containing the Flask application.
- app: An instance of the Flask class in the main Python file 'api.py'.
- Load Balancer: You can configure nginx to handle all the test requests across all the gunicorn workers, where each worker has its own API with the DL model.
- Load / Performance Testing: Take a stab at Apache Jmeter, an open-source application designed to load test and measure performance. This will also help in understanding nginx load distribution.
Production Setup
- Cloud Platform: After you have chosen the cloud service, set up a machine or instance from a standard Ubuntu image (preferably the latest LTS version). The choice of CPU machine really depends on the DL model and the use case. Once the machine is running, setup nginx, Python virtual environment, install all the dependencies and copy the API. Finally, try running the API with the model (it might take a while to load all the model(s) based on the number of workers that are defined for gunicorn).
- Custom API image: Ensure the API is working smoothly and then snapshot the instance to create the custom image that contains the API and model(s). Snapshot will preserve all the settings of the application.
- Load Balancer: Create a load balancer from the cloud service, it can be either public or private based on the requirement.
- A Cluster of instances: Use the previously created custom API image to launch a cluster of instances.
- Load Balancer for the Cluster: Now, link the cluster of instances to a load balancer, this will ensure the load balancer to distribute work equally among all the instances.
- Load/Performance Test: Just like the load/performance testing in the development, a similar procedure can be replicated in production, but now with millions of requests. Try breaking the architecture to check it’s stability and reliability (not always advisable).
- Wrap-up: Finally, if everything works as expected, you’ll have your first production level DL architecture to serve millions of requests.
Additional Setup (Add-ons)
Apart from the usual setup, there are few other things to take care of to make the setup self-sustaining for the long run.
- Auto-scaling: It is a feature in cloud service that helps in scaling up the instances in for the application based on the number of requests received. We can scale-out when there is a spike in the requests and scale-in when the requests have reduced.
- Application updates: There comes a time when you have to update the application with a latest DL model or update the features of the application, but how to update all the instances without affecting the behavior of the application in production. Cloud services provide a way to perform this task in various ways and they can be very specific to a particular cloud service provider.
- Continuous Integration: It refers to the build and unit testing stages of the software release process. Every revision that is committed triggers an automated build and test. This can be used to deploy latest versions of the models into production.

Alternate platforms
There are other systems that provide a structured way to deploy and serve models in the production and few such systems are as follows:
- TensorFlow Serving: It is an open-source platform software library for serving machine learning models. It’s primary objective based on the inference aspect of machine learning, taking trained models after training and managing their lifetimes. It has out-of-the-box support for TensorFlow models.

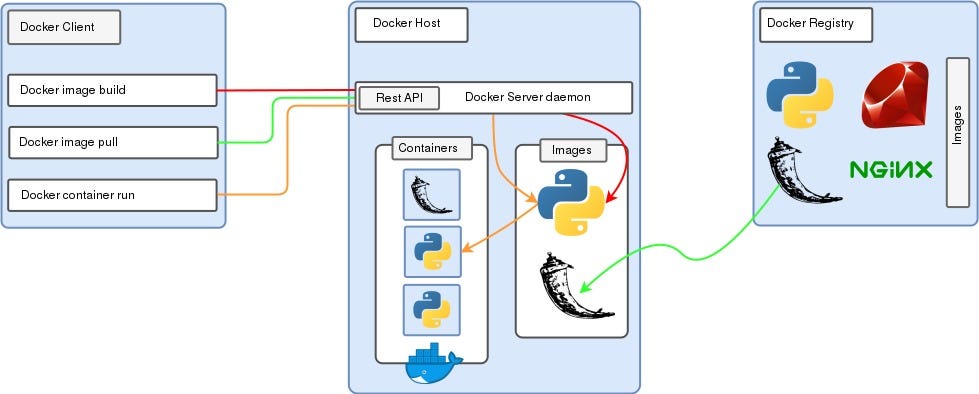
- Docker: It is a container virtualization technology which behaves similarly to a light-weighted virtual machine. It provides a neat way to isolate an application with its dependencies for later use in any operating system. We can have multiple docker images with different applications running on the same instance but without sharing the same resources
- Michelangelo: It is Uber’s Machine Learning platform, which includes building, deploying and operating ML solutions at Uber’s scale.

 ARTICLE
ARTICLE
 11 min read
11 min read








 Comment
Comment







SAI 16 Sep, 2022
What if I do not have reliable internet connection at deployment site. In that case, can I simply load each trained model in a low end device like Rasp.pi? Do I need all these setup? What would be the minimum internet connection speed to use this seamlessly per camera/device in general?
Astha 16 Sep, 2022
This is a good guide. I am just curious about where to deploy the model. Is it better to just put it in the same image where the flask resides and just load it as is or put it in a storage provision such as cloud bucket or storage? If the former, then would that mean different API servers for different models… am I right with this thought? And would that better serve production quality or not?
Vinay 16 Sep, 2022
Thanks for this great article, I think it will help a lot of people as so many ML projects are failing because of this deployment part... If you're ok I'd also like to mention an out of the box service for NLP models deployment in production that I discovered recently: https://nlpcloud.io Very useful IMO for people who don't want to spend too much time on DevOps.